
ComfyUI 是一个基于节点流程式的Stable Diffusion UI,是一个开源的基于图形界面Workflow可视化引擎,你可以把它想象成集成了Stable Diffusion功能的Substance Designer,通过将Stable Diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。但节点式的工作流也提高了一部分使用门槛。
SD1.x工作流程
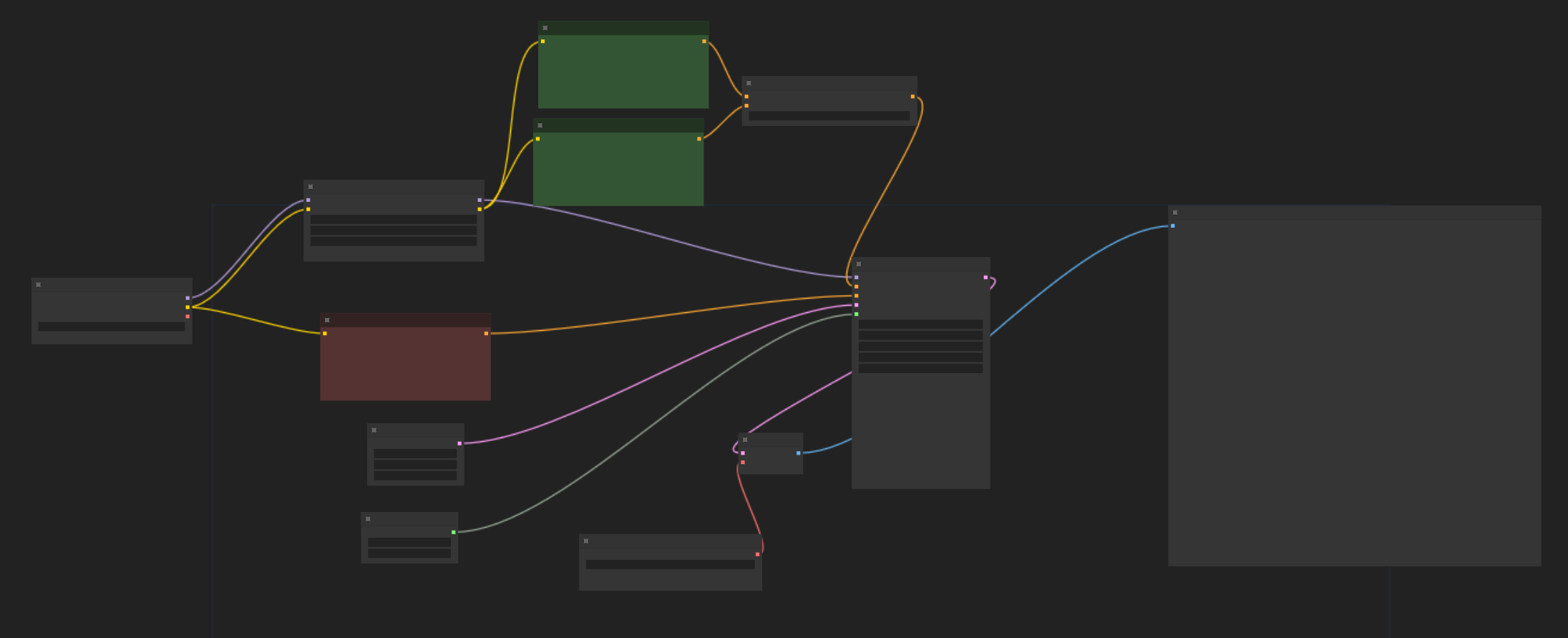
最简单的图像生成工作流程。我们将检查第一个工作流程的各个方面,因为它将让你更好地了解稳定扩散的工作原理,但这并不是我们会对每个工作流程执行的操作,因为我们主要通过示例进行学习。

- 首先加载一个检查点
- 接下来我们设置潜在尺寸。了解潜在空间和像素空间之间的区别很重要。图像实际上是在一个特殊的环境中处理的,其中包含对模型有用但对我们来说不是很多的信息。这个环境就是潜在的。计算完成后,数据可以转换为我们可以看到的东西,即:像素。此阶段发生在上图中的第 5 步“Vae 解码”。
- 是时候添加正面和负面提示了。文本必须翻译成机器可以理解的语言。此转换由 CLIP 模型执行(因此节点名称为“CLIP Text Encode”)。
- 如果检查点是大脑,那么 KSampler 就是心脏。我们现在拥有处理一些数字所需的所有数据。我们需要设置的主要参数如下:
- 种子:这是用于生成随机数的种子的数字。不同的种子=不同的形象。
- 步数: 步骤:达到最终图像所用的步骤数。更多的步骤需要更多的时间来计算,但可能会获得更好的组合。根据提示、采样器和检查点的不同,情况会有很大差异,我们通常从 15-20 的值开始。
- CFG: 无分类器指导尺度定义图像与提示的接近程度。数字越低,模型越接近你的方向(即:迭代概念的时间越少)。如果你尝试创建模型未直接训练的复杂图像,则较高的 CFG 可能有助于合成。一般来说,4 到 9 之间的值应该涵盖你的所有用例,但这取决于许多因素,包括你正在使用的检查点。
- 采样器和调度器:一起负责在潜在空间中进行噪声处理,直到在定义的步骤内达到最终图像。某些采样器可能会以较少的步骤达到良好的结果,但速度可能会较慢。
- 最后,感谢 VAEDecode 节点,将潜在图像转换为我们可以看到的图像。请注意,转换是有损的,并且计算量很大,因此在实验过程中,你可以在潜在空间内进行的工作越多越好。
💡 **提示:**每个节点上的连接“点”都有一种颜色,该颜色可以帮助你了解节点应该连接到/从哪里连接。
💡 **提示:**如果图像看起来过饱和或对比度过高,请尝试降低 CFG 比例。
外挂VAE模型
VAE是在 “潜空间” 与 “像素空间” 之间的一个桥梁。像素空间就是我们人眼看的正常图片。编码器负责将图像压缩到潜空间中的低维表示,而解码器从潜空间恢复图像。
通过外挂VAE模型可以一定程度上改善图片质量:

批量生图
当 KSampler 完成后,我们可以像之前一样正常显示四张图像,并只提取我们喜欢的一张图片。

参数化节点选项
大多数节点参数可以转换为可以连接到外部值的输入,这在处理复杂的工作流程时非常有用,因为它允许你为多个节点重用相同的选项。

使用LoRA
LoRA之间相互级联
只需要将Checkpoint加载器输出的模型和CLIP连接LoRA加载器即可

使用的是MoreDetails的LoRA模型,增加细节丰富度(LoRA玩法可以非常多)

CLIP停止层
你可以将 CLIP 想象为一系列层,它们逐渐精确地描述你的提示。假设你有一个类似“一位年轻女子站在草地上”的提示。第一层可以是“一个女人”,在第二层中我们添加她“年轻”,在第三层中我们添加她“站在草地上”等等。当然,没那么简单,只是给你一个想法。通过设置最后一层,你可以主动限制 CLIP 描述图像的深度。
它用负值表示,其中-1表示不“CLIP跳过”。

下面是对比图(左图是CLIP停止层为-1,右图是CLIP停止层为-2):

放大图片
在我们继续之前,了解几个重要概念很重要:
- 潜在空间和像素空间之间的差异
- 传统图片放大和基于机器学习的图片放大之间的区别
- 降噪的影响
图像生成实际上发生在所谓的“潜在空间”中。潜在是 GPU(或 CPU)处理所有数据的地方;该信息需要由模型(VAE)解释才能转换为像素。潜在解码是一个有损过程,需要计算能力,图像越大,需要的资源就越多。这就是为什么只要有可能,我们就会尝试在潜在空间内工作并仅在最后阶段转换为像素。
为了放大图像,我们可以使用双三次、双线性等传统算法或为此目的训练的机器学习模型。当然,传统方法速度更快,但结果通常很模糊,具体取决于放大因素。为了恢复细节和清晰度,我们可以对放大的图像应用第二遍。这包括将图像传递给第二个K采样器并使用降噪参数。
噪点越低,图像看起来越接近原始图像,但第二遍的影响也越小。如果你不关心最终图像是否与原始图像 1:1,你可以增加降噪并获得非常清晰的结果,尽管与起始生成略有不同。当在像素空间中放大时,0.25 到 0.5 之间的降噪足以获得良好的结果。当然,基于模型的放大器将需要较低的噪声,因为放大后的图像应该已经相当不错了。
总而言之:一旦使用任何方法放大图像,请使用尽可能低的降噪因子,以获得最佳结果。
操作方法是在最后VAE解码后再接一个放大图片的模型进行处理

下面是结果的对比

调整词权重
**这非常简单且广泛,但无论如何还是值得一提。**具体是你可以通过将单词或一系列单词放在括号内来赋予更高(或更低)的权重。
比如我们生成一张图片:
Close-up photo of a cat wearing sunglasses and carrying a bag eating a burger
## 特写一张戴墨镜背着包的猫咪吃汉堡的照片
在此示例中,我们为“吃汉堡”赋予稍高的权重。
Close-up photo of a cat wearing sunglasses and carrying a bag (eating a burger)
## 特写一张戴墨镜背着包的猫咪吃汉堡的照片
我们还不满意,还可以继续添加括号:
Close-up photo of a cat wearing sunglasses and carrying a bag ((eating a burger))
## 特写一张戴墨镜背着包的猫咪吃汉堡的照片
强调多次之后,我们的小猫总算吃上了汉堡。
除此之外,我们还可以为提示词添加具体的权重:(eating a burger:1.1)或者(eating a burger:0.5)等等。
💡提示:
(eating a burger:1.1)相当于(eating a burger)
条件连接
该模型通常不擅长理解多个概念以及将不同元素的特征置于上下文中。例如,指定不同颜色的对象可能非常困难。
A red box and a green ball on the road
## 一个红箱子和一个绿色球在马路上
可以看到只有第一幅图的颜色是对的,其他三幅都是错的。
通过条件连接,可以建立两者之间的联系,将不同元素的特征准确表达

